

- 手机:
- 13564805630
- 电话:
- 021-57708796
- 邮箱:
- 838717855@qq.com
- 地址:
- 上海市奉贤区民乐路88号3幢110室
2023年8月,吴新宙算是在中国L2+智能辅助驾驶竞争顶峰--辅助驾驶进城之后离开小鹏汽车加入英伟达。2024年1月,特斯拉推出FSD V12 Beta端到端版本,智能辅助驾驶算法进入“端到端”阶段。随即中国代表了全球辅助驾驶市场全面拥抱了端到端。
不过,此时的自动驾驶领域中,吴新宙带领的英伟达自动驾驶好像已经淹没在端到端自动驾驶+高端芯片自研的自动驾驶竞赛中,甚至英伟达4月份的GTC上也不过一分钟过一下老生常谈的车端方案和云端训练硬件,而吴新宙自己主导的专项GTC演讲,虽然有VLM,但产品路线图也没看到什么新意。
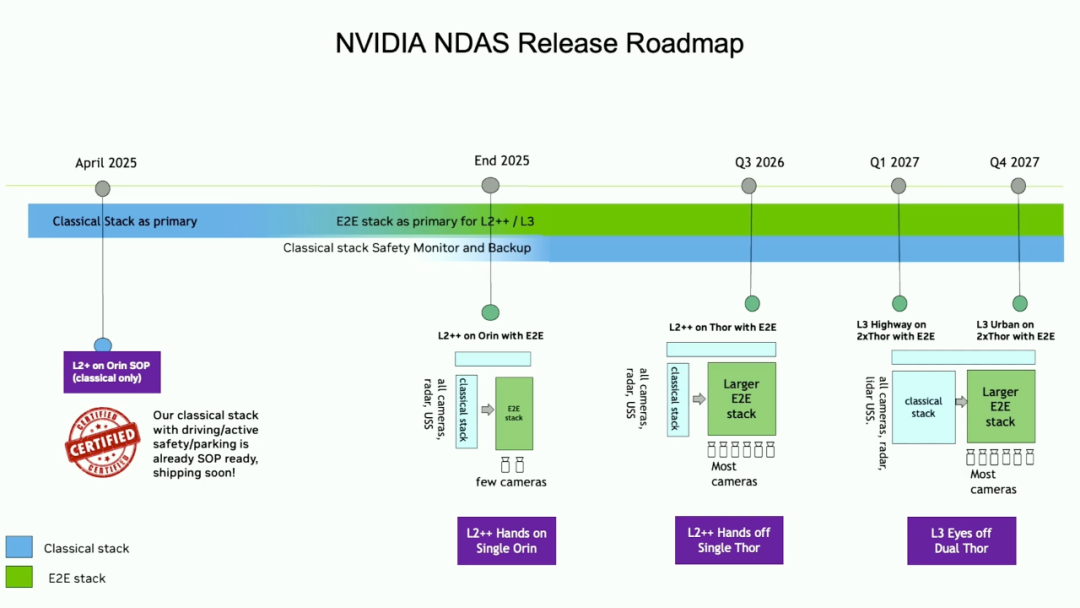
到了,今年10月的GTC,我们之前文章《英伟达 GTC 2025:6G通讯、量子计算、L4自动驾驶方面三大全新产品技术》也分享了,黄仁勋机竟然花了五分钟广告其L4 Robotaxi要点和成绩。
与 Uber 合作,从2027年开始会有10万辆采用英伟达方案的自动驾驶车辆。Lucid、奔驰、Stellantis 等主机厂和十几家自动驾驶开发公司采用英伟达的L4软硬方案。
于是,吴新宙应该是带领英伟达找到了冲刺L4新征程的方向,这个冲刺新征程背后除了英伟达的AI硬件,还有一种新的VLA软件。
很多人会说,为什么不是世界模型?这是最前沿的,确实世界模型是最前沿的,可是理论世界的两大世界模型的领军人物Li feifei还在摇旗呐喊demo阶段,Yann LeCun刚从Meta失业,所以怎么可能真的世界模型就能上应用呢!
当前大家讲的世界模型不过依然是通过LLM将物理世界语言化和图形化的模型,与VLA是同一个分支。而线D世界+时间的隐式表达token的世界模型还在实验室寻找中。
最近英伟达公布了其名为Alpamayo-R1 的VLA模型一些思路和想法,应该就是英伟达推进L4落地的一些方法和实践,应该属于当前技术产品化的最先进方向。
所以,本文就从VLA当前结构和挑战,英伟达L4 VLA 算法结构,英伟达L4 VLA数据标注和训练方法来分享解析这个VLA算法。
熟悉我们之前VLA的文章朋友们肯定知道,VLA可以通过语言模型来进行理解和推理人类世界,这样将智能辅助驾驶相比之前纯粹的端到端有了以下几个优点:
VLM/VLA 已被几家头部应用于自动驾驶,不过,虽然都叫VLA,但是当前不少VLA可能本质还是一个VA:
也就是大多为反应性地操作而没有明确推理,难以泛化到需要反事实推理的模糊或长时域场景。
此外,简单的将自动驾驶的推理视为纯粹的自然语言处理(NLP)问题,会忽略驾驶需要丰富的3D和物理空间知识:车道几何、交通规则、智能体交互和动态约束。
于是,英伟达的自动驾驶VLA模型 Alpamayo-R1 采用以下创新方法来
开发了一个结构化的因果链(CoC)标注框架,该框架生成以决策为基础、具有因果关联的推理痕迹,并通过混合的人工参与和自动标注流程支持可扩展的高质量数据生成。
采用了基于流匹配(flow matching)的扩散型行动专家轨迹解码器,以高效地生成连续的、多模态轨迹规划,这些规划与语言推理输出对齐,并满足实时推理要求。
采用多阶段训练策略,基于 Cosmos-Reason VLM 主干,注入行动模态进行轨迹预测,通过在 CoC 数据上进行监督微调(SFT)来激发推理能力,并采用强化学习(RL)来提升推理质量、推理-行动一致性及轨迹质量。
其实所有的 VLA就是一种端到端架构。英伟达AR1也不例外,系统处理多摄像头、多时间步观察作为视觉输入,可选择性地增强语音文本输入,如用户命令和高级导航指令。所有输入都被 Token 化为统一的多模态 Token 序列,然后由 Cosmos-Reason 这个VLM主干处理。
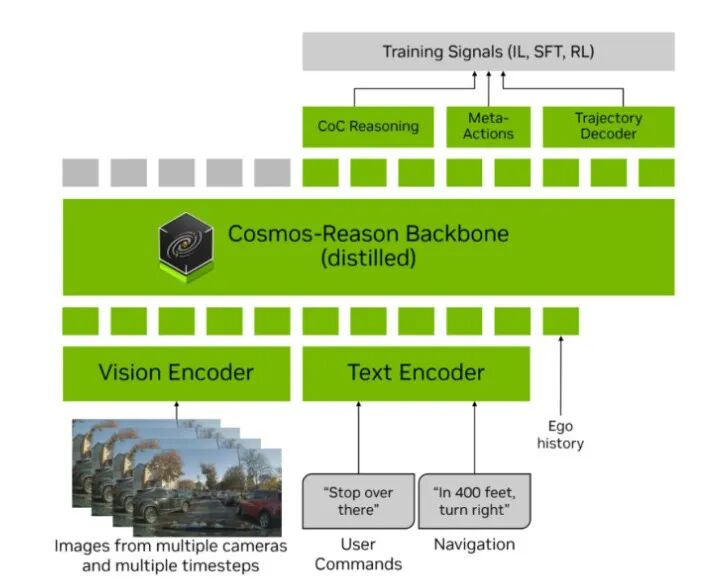
当前来讲 VLM模型算是易得,但是好的数据难求,英伟达AR1让他每一个动作和行为都有明确的推理和解释,微调训练的数据就必须要有这些东西。
所以,英伟达 AR1整理和标注好2.47万个驾驶的视频和问答推理,来微调这个VLM。2.47万个视频包含描述和问答推理,这是个巨大的工作量,后文我们有分享英伟达数据标注方法。
有了这个特调的VLM,那么VLA另外两个重要的事情就是把输入的视觉和语言进行编码进入VLM,另一方面就是把VLM吐出来的东西解码成运动轨迹。
输入的视觉编码 (Vision Encoding),对于自动驾驶来讲,计算的成本是有限的,所以VLM 中的视觉编码器必须产生尽可能少的 Token,同时保留相关的语义信息,以实现车载部署。英伟达AR1研究过和采用的方法是:
单个摄像头单帧编码,例如,对于 448x280 像素的图像,此过程为每张图像生成 160 个 Token。由于自动驾驶车辆通常使用 6 到 10 个摄像头,单图像 Token 化产生的 Token 数量会随摄像头数量线性增加,从而妨碍实时推理。
多摄像头单帧同步编码,可以采用 3D 归纳偏置的方法使 Token 数量与摄像头的数量和分辨率解耦。例如,对于 7 摄像头设置,只需 288 个 Token 即可表示一个时间步的观察结果。
多摄像头视频编码:对来自多个时间步的摄像头观察序列进行直接编码,压缩率为高达 20 倍(相比单图像 Token 化),同时保持或甚至改善下游驾驶指标。
显然英伟达AR1 应该是应用了多摄像头同步编码的方式,来节省算力需求,毕竟车端部署,算力和实时性是最大的约束,谁能算的快算的准是AI的要求。
当然还有语音文本的模态,这个输入对于VLM就是信手拈来,毕竟原生就是LLM。
一般VLA的VLM内部吐出的是基于车辆的位置轨迹,但是,这种原始位置(x, y)路径点空间训练模型容易受到传感器噪声的影响,后面在平滑处理,最后带来更多不准确的信息。
因此,英伟达AR1提出了单轮动态学(unicycle dynamics) 控制的行动表示。x和y表示鸟瞰图(BEV)平面中的位置航点,表示偏航角,v表示速度,k表示曲率,a表示加速度。并将这些参数映射到VLM中,共用一套Token。
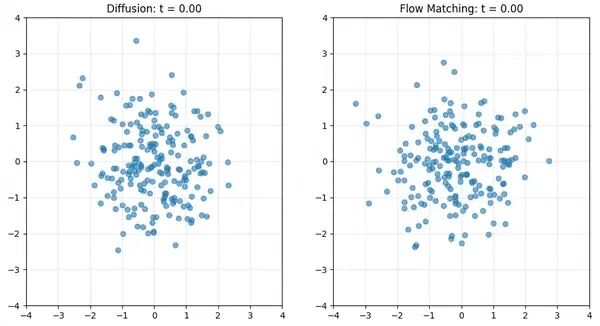
最后,行动专家使用Flow Matching 框架和我们之前文章分享的Diffusion 扩散模型一样,两者都致力于将噪声转化为结构化数据,也就最后输出自动驾驶输出的控车信息。
这样,使得推理和轨迹共享一个共同的 Token 空间,允许 VLM 通过标准下一 Token 预测紧密耦合因果解释与车辆行为。
同时,Flow Matching提供了计算效率,生成连续轨迹的速度比自回归采样 128 个离散 Token 快得多,从而实现了实时推理。
所以,英伟达AR1 VLA模型将VLA模型组合的更紧密了,有点像流水线从原材料到包装发运到在一条产线上。
英伟达AR1 的推理和轨迹共享一个共同的 Token 空间就必须让之前训练的数据结构发生变化。推理数据必须与自我轨迹紧密相关,才能使推理 VLA 模型能够解释驾驶行动的原因并提高其轨迹性能。
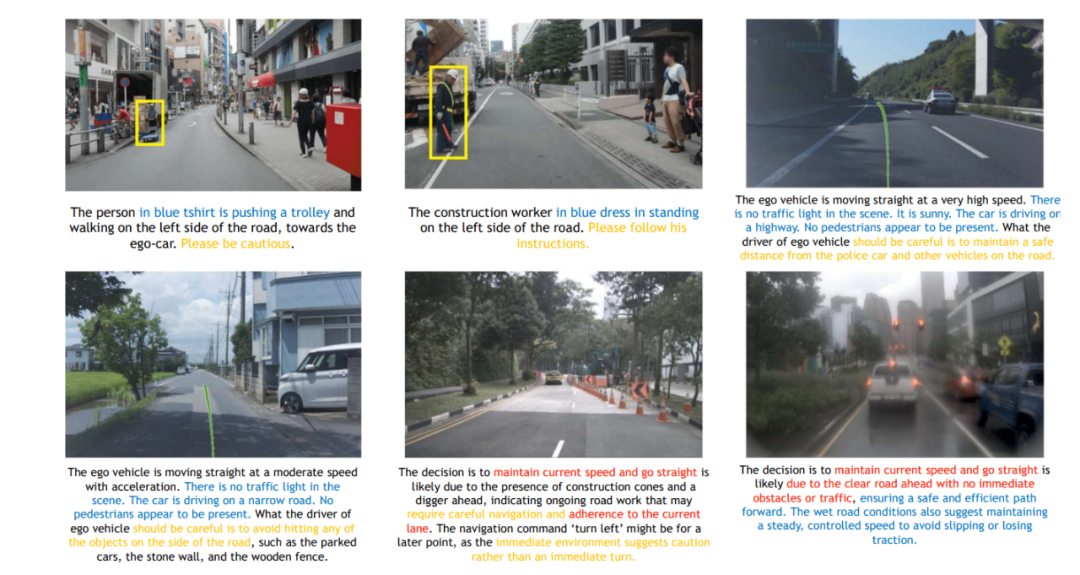
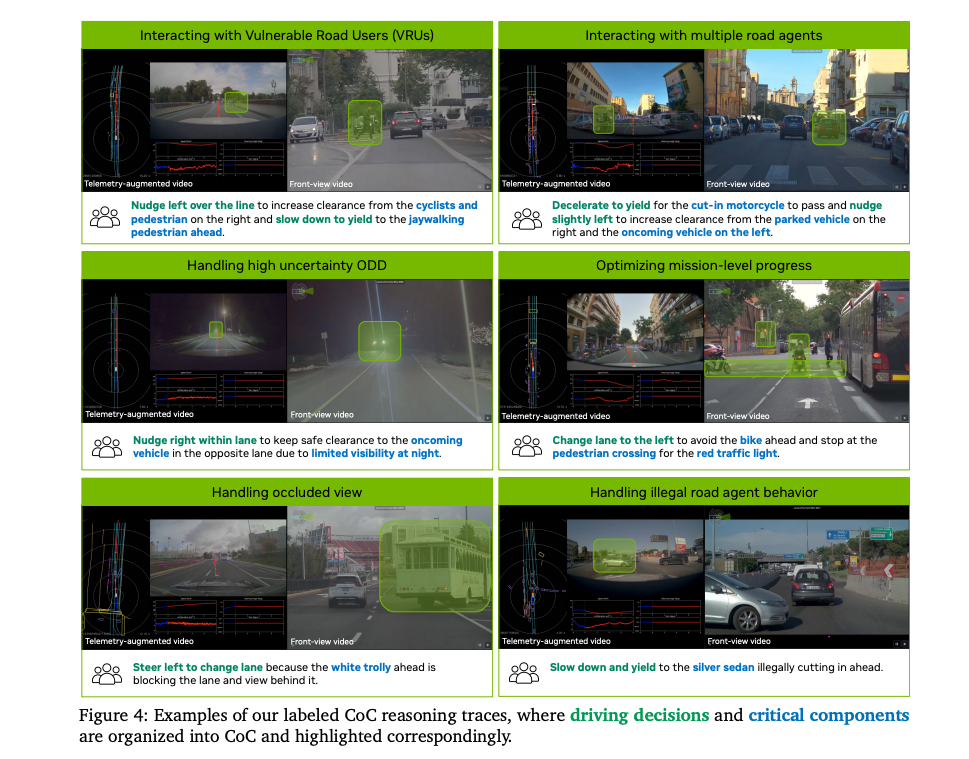
Alpamayo-R1 模型训练的标注框架将每个数据样本分解为三个结构化组件:驾驶决策、因果因素(关键组件) 和组合推理痕迹。
自动驾驶决策的分类表,它定义了模型必须学习的各种纵向和横向驾驶动作及其具体的含义。


最后就是输出组合的推理痕迹,它强调了在识别出驾驶决策和关键场景组件后,如何将其语言化并组织成连贯、具有因果逻辑的解释。
有了这些规则,同时在实际标注时候,为了确保训练数据的高质量和实用性,标注时候需要考虑:
同时这是为了实现标注经济性,聚焦于最关键、最直接的因素。例如,如果汽车停了下来,是因为前车刹车(近端原因),而不是因为前面有一个红灯(背景条件);
最后是,决策最小化: 确保只在决策发生变化时才生成新的推理轨迹,从而提高数据效率和模型的注意力集中度。
但,标注之前是确定应该在何时标记这些推理数据。因为,并非每个视频片段都值得标注;只有在可观察因素与自车随后的决策之间能建立明确因果联系的时刻,才会触发标注。因此,数据管理是数据标注框架的一个关键方面,它涉及到识别这些关键的推理时刻。
英伟达AR1 每个数据的原始片段包含 20 秒的数据,并且可以生成多个训练样本(因为在训练和评估中都配置使用 2 秒历史来预测 6 秒未来)。
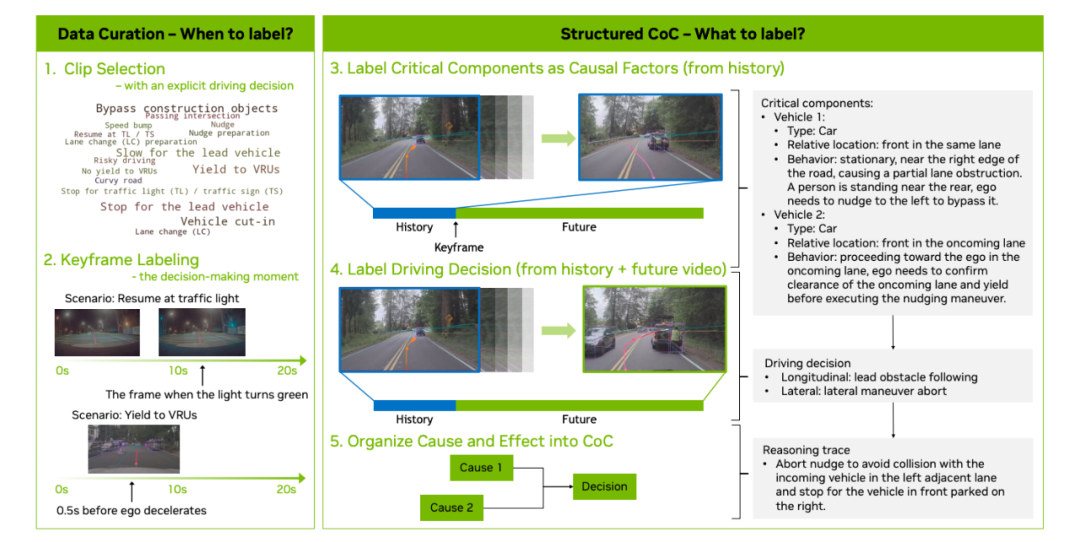
阶段 I (0-2 s):在可观察的历史窗口内识别关键组件,以防止因果混淆。
阶段 II (0-8 s):选择关键帧后的第一个驾驶决策,并撰写 CoC 推理痕迹,仅引用阶段 I 中确定的因果因素。我们实施了严格的 QA 流程来最大化标注质量。
自动标注:使用最先进的 VLM(如 GPT-5 (OpenAI, 2025))进行离线自动标注。该流程将世界知识蒸馏到结构化的 CoC 标注中。自动标注 VLM 被提示使用 2 秒的历史视频来识别关键组件。
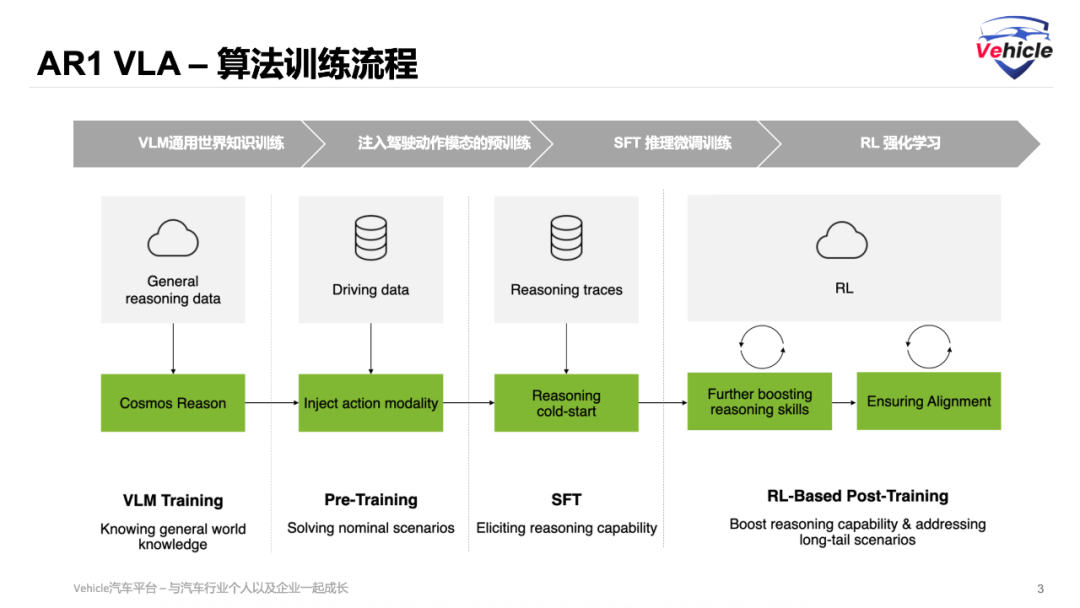
当前VLA模型的训练算是统一标配了,之前文章《揭秘小鹏自动驾驶「基座模型」和 「VLA大模型」》也分享过类似的训练流程。
之后,SFT提升推理能力 (Improving Reasoning Capability) 对应 SFT,提高模型的推理能力,使其能够生成因果基础的解释来支持驾驶决策。这里就需要上文讲到的在2.47万的CoC 数据集,在它上进行有监督微调 (SFT)。
这样VLA可以生成因果基础的解释,使模型能够提供可解释且更好的驾驶决策。
最后,RL 的强化学习后训练,构建奖励模型,来强化人类想要的东西,英伟达AR1 利用大型推理模型的反馈来精炼推理质量。最终将推理轨迹与实际执行的动作对齐。最终VLA模型产生可解释且安全的驾驶行为,并优化整体轨迹质量。
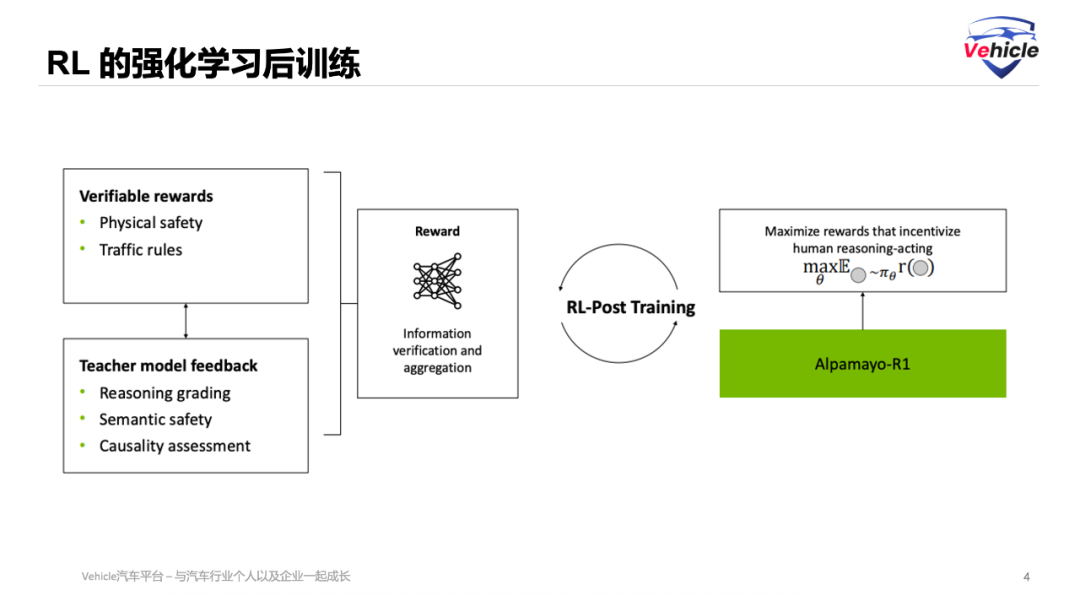
利用大型推理模型进行推理评分,利用DeepSeek-R1 作为推理批评家,对 VLA 生成的推理痕迹质量提供可扩展、高质量的反馈。评估行为一致性和因果推理质量。鼓励模型生成不仅描述正确驾驶行为,而且保持因果忠实性的推理。
数据集CoC-行动一致性:CoC-动作一致性奖励通过将模型的语言输出(推理)与其物理输出(动作)进行硬性、基于规则的匹配,确保了模型的解释性和可靠性,是实现可信赖自主驾驶的关键环节。
低级轨迹质量,也就是输出运动控制: 确保生成的运动轨迹在物理上可行、舒适且安全。主要是三个方面:轨迹曲线平滑类人。碰撞惩罚和加加速度(Jerk)惩罚,以惩罚突然或不舒服的运动。这些项将模型的学习锚定到类人、安全和舒适的运动。
这样基本就完成了整个VLA的构建,后续模型升级就是根据回传的极端场景进行修复和优化。
吴新宙,确实是个人才,进入英伟达时候算是高位接盘,在L2+这么卷的市场已经很难有建树,到现在,用最前沿能到手的技术开辟了一个L4战场,算是给职业生涯接上了另外一棒。
而对于算法,VLA在当前大语言模型应用成熟,空间智能还在实验室的背景下,确实是实现自动驾驶产品化的最优解。
机器人奥运会战报:宇树机器人摘下首金,天工Ultra抢走首位“百米飞人”
